This is a follow-up to the previous post that
described how it is now possible to insert a PDF file as an image in
LibreOffice and export that back to PDF, while keeping the original PDF
contents. I’ve recently improved this feature so the resulting file is smaller
and the vector image can be viewed in more viewers. First, thanks to
PMG who made this work possible.
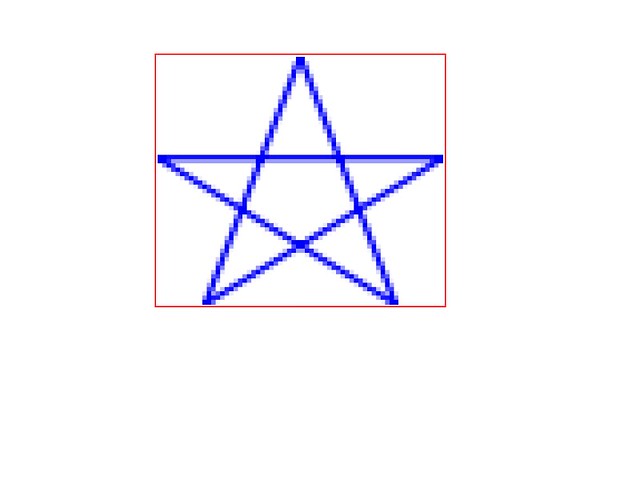
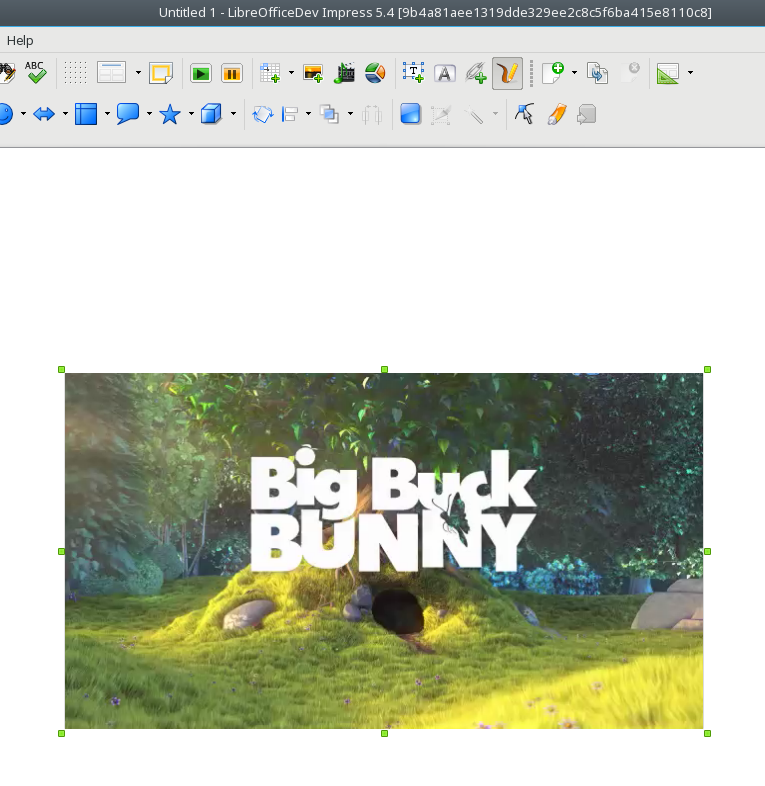
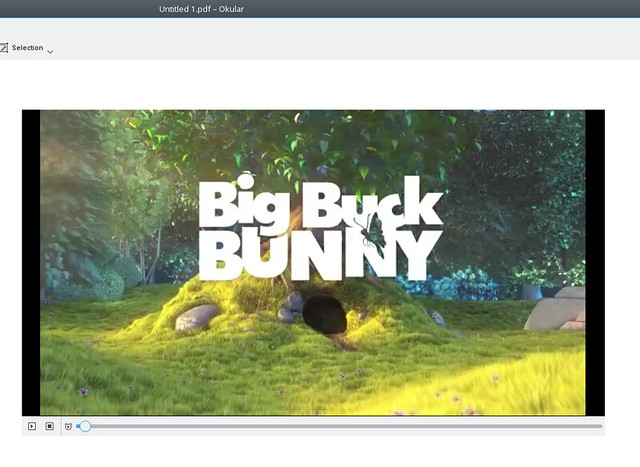
Let’s look at the previously mentioned front page of a magazine sample when
it’s viewed in okular. (A KDE pdf viewer, i.e. something that’s not Adobe
Acrobat). The previously used reference XObject PDF markup is not handled by
it, so the bitmap fallback was displayed:
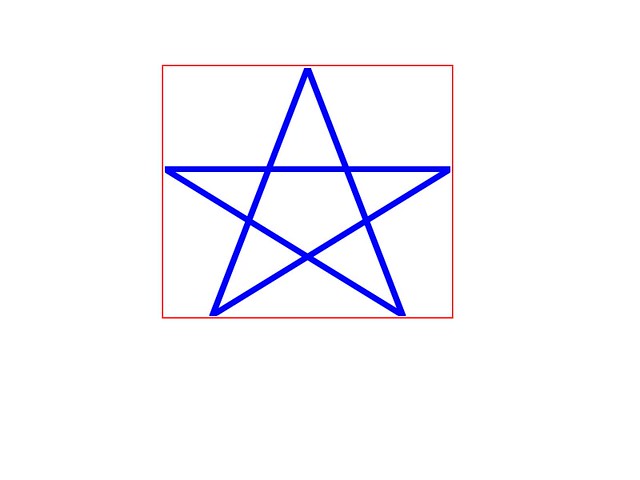
Compare it with the new result:
Notice the sharp text in the first line.
Also the size of this sample is smaller now, since we don’t write a large
bitmap, and the not shown second page of the PDF image: 2 385 984 → 1 605 558
bytes (about one third of the output is avoided).
Both techniques have pros and cons, here is a summary:
-
The reference XObject approach allows you to preserve the full PDF data of
the image: if it was of multiple pages, even that. Also, the LibreOffice
code for this is simple: we just preserve a byte array — that can hardly go
wrong. The problem is that no non-Acrobat PDF viewer implements this,
including e.g. your printer most probably.
-
The new approach uses the tokenizer I originally wrote for
PDF signature verification purposes — it extracts
the page stream of the first page from the original file and uses it as a
form XObject in the export result — this is the same as how e.g. pdfcrop
works. This markup is handled by almost all PDF viewers and also the
resulting size is smaller, since the data of other pages is dropped and there
is no fallback bitmap. The problem may be that this is a much more complex
scenario, so it may go wrong (as usual, bugreports
are
welcome).
Nevertheless, the new approach seems like a much better default, so
LibreOffice no longer writes the reference XObject approach unless you
explicitly request it in the PDF export dialog.
Some perhaps interesting details:
-
PDF page streams may be provided by multiple objects, but form XObjects must
have a single stream, so it we handle the case when different parts of the
page stream are compressed in different ways.
-
LibreOffice writes PDF-1.4 by default, in case you insert a PDF image that
uses PDF-1.5+, we use pdfium to downgrade that markup to 1.4, and only
then insert it.
-
Copying the page stream of the image is not enough, we also recursively copy
all referenced objects from the source PDF, while rewriting all contained
references, since the objects IDs in the old and new files differ. We also
take care of proper scoping of named references in the resource dictionary, so
you can use this feature recursively (insert a document as a PDF image, even
if that document itself contains PDF images already). :-)
All this is available in LibreOffice master, towards 5.4.