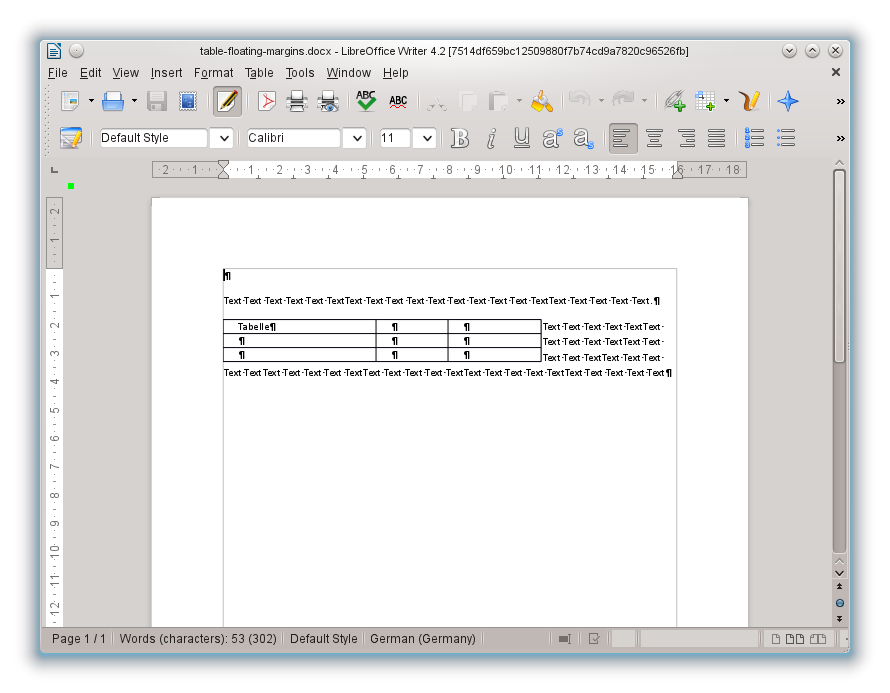
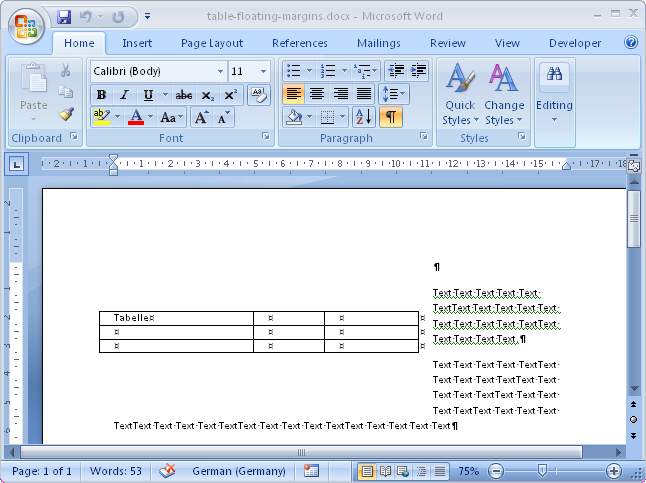
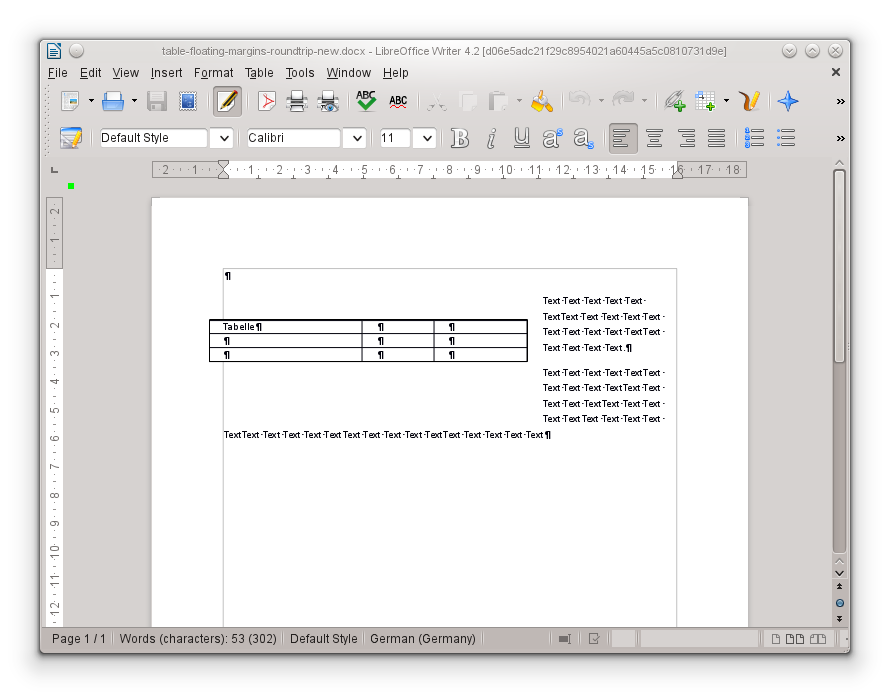
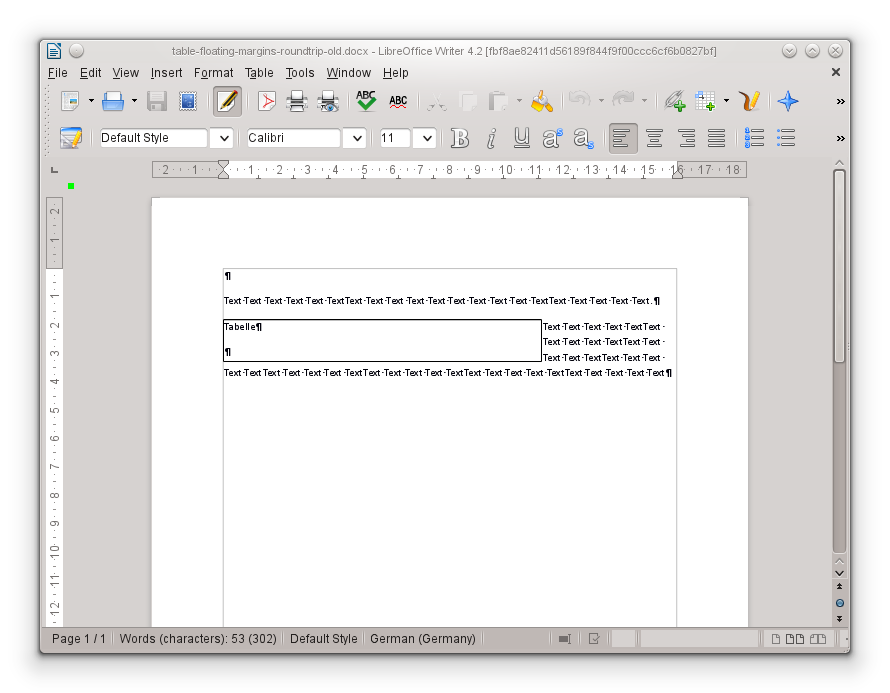
I just checked, I created my git push tree more than a year ago, but
yesterday I was reminded that this technique isn’t really documented anywhere,
so let me describe it.
Some background: for the LibreOffice codebase, we decided to do all
micro-features directly on the master branch. This means that we typically
rebase our local master branch against origin/master, then push it. The
benefit of this is that code gets wider testing quickly and the commit history
is not polluted with meaningless merge commits.
The problem: one drawback of the above situation is that after you pull, some
changes of other developers in the lower layers may trigger a full rebuild,
typically wasting about an hour of your life (or more, in case of slower
machines).
Push tree is one hack to avoid this problem. Using a push tree, you have two
separate repositories locally, you update your main one less regularly, and
when you have a commit to push, you push it from the push tree to be able to
avoid pulling in your main tree.
Here is how to do it. To set this up:
git clone --reference /path/to/master ssh://logerrit/core master-push
Then to use it, instead of git pull -r && git push in your master tree, do these:
cd /path/to/master
git show -s <1>
cd /path/to/master-push
git pull -r
git cherry-pick $sha1 <2>
git push
-
copy the sha1 hash from the output
-
replace $sha1 with the sha1 hash you got in the previous step
(There is a trick here, given that master-push already references the original
tree, you can go ahead with cherry-pick directly, without fetching branches
from your master tree.)
And that’s it, you were able to push without waiting for a long rebuild!
Note: of course this technique has some drawbacks as well, so use with care.
Keep in mind the followings:
-
If your local master is not up-to-date enough, you’ll get conflicts while
cherry-picking. I usually update my master tree once a day in the morning.
If you have a slower machine, do it once a week in the night, or so.
-
Even if you don’t get conflicts, there can be cases when the result of the
cherry-pick in the push tree won’t be what you want. Chances that this
happens is pretty low if your master tree is not super-old, see the previous
note.
-
An other non-technical but social reason to still update your master tree
regularly is that if everyone uses an infrequently updated master tree,
then nobody will fix breakages caused by others on origin/master. So updating
your real tree infrequently is a bit unfair to other developers.
Other than these, I can just recommend using a push tree, it helped me many
times not to loose focus in the middle of the day. (And as we all know, pushing
all your risky changes on Friday afternoon is also a bad idea. :-) )