Estimated read time: 2 minutes
Inter-dependent change tracking in Collabora Online was mostly a topic last year, see the post from November for more info about the feature in general: this is the case when you create a change on top of another change.
This post is meant to deal with the situation where you already have a recorded formatting and somebody else creates a new formatting on top of that.
Motivation¶
Writer supports insert-then-delete, insert-then-format and delete-then-format as combinations of changes with different types. So format-on-format is not supported at a file format level, DOCX can't represent it, either.
But instead of just losing the old format when we create a new format, we can do better: update the format redline to now track the formatting of the union of the old and new format change.
This still means that the metadata (e.g. author) will be only stored for the new change, but accept or reject on the format will result in the expected formatting.
Results so far¶
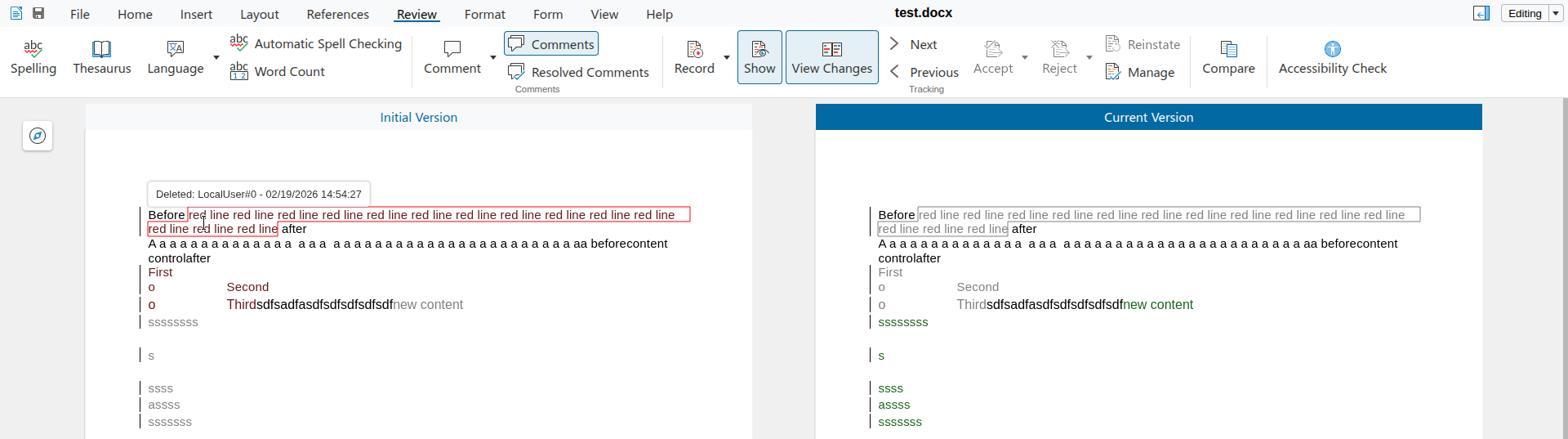
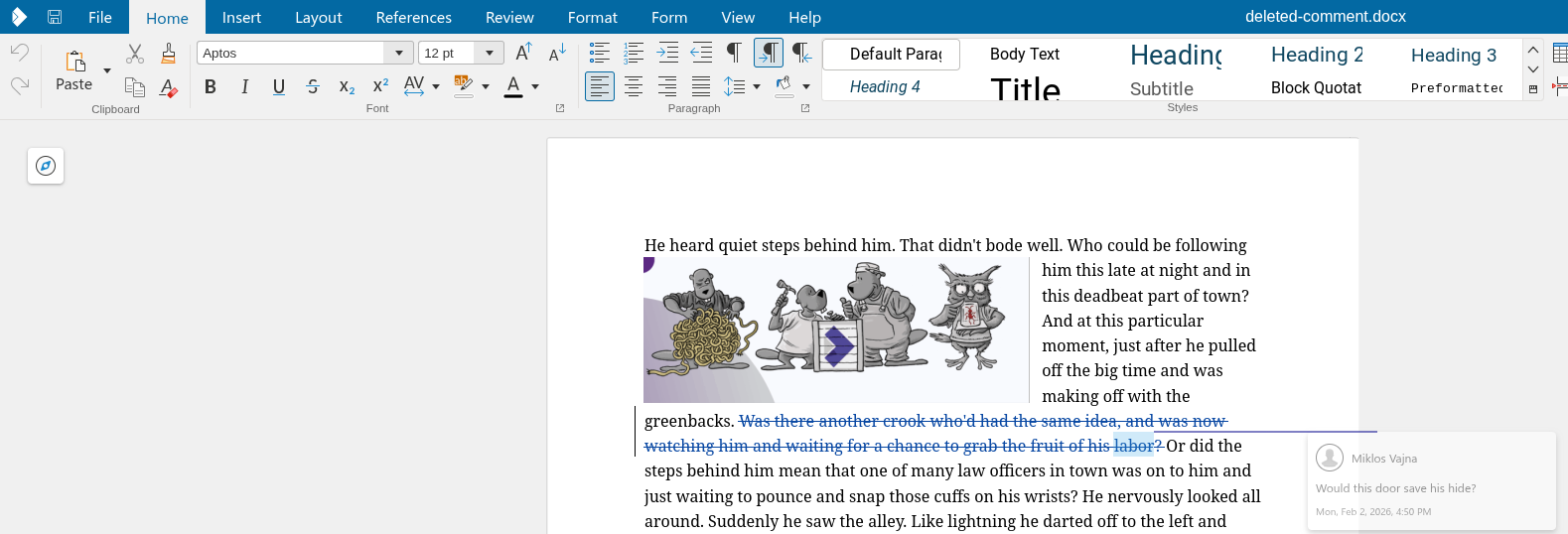
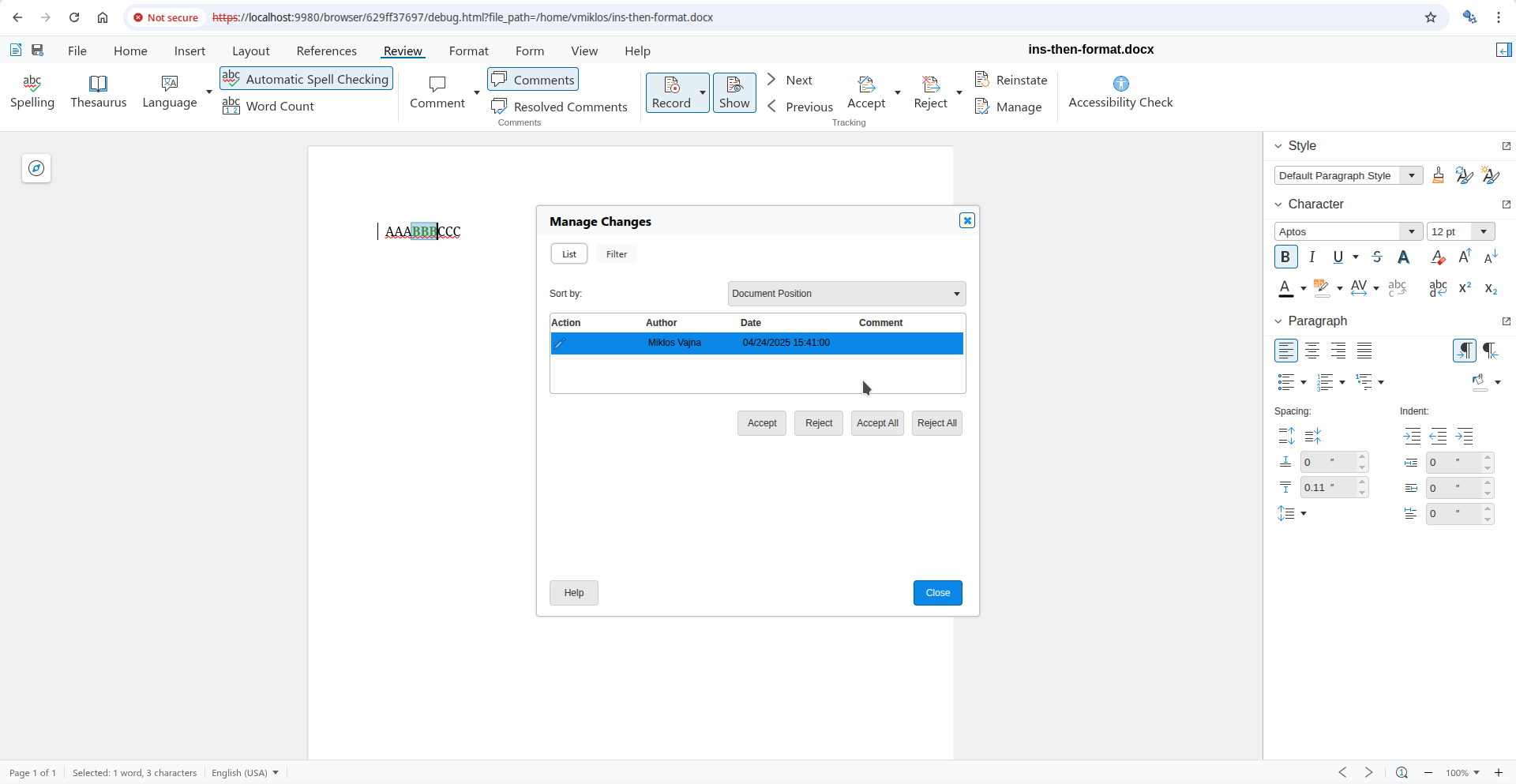
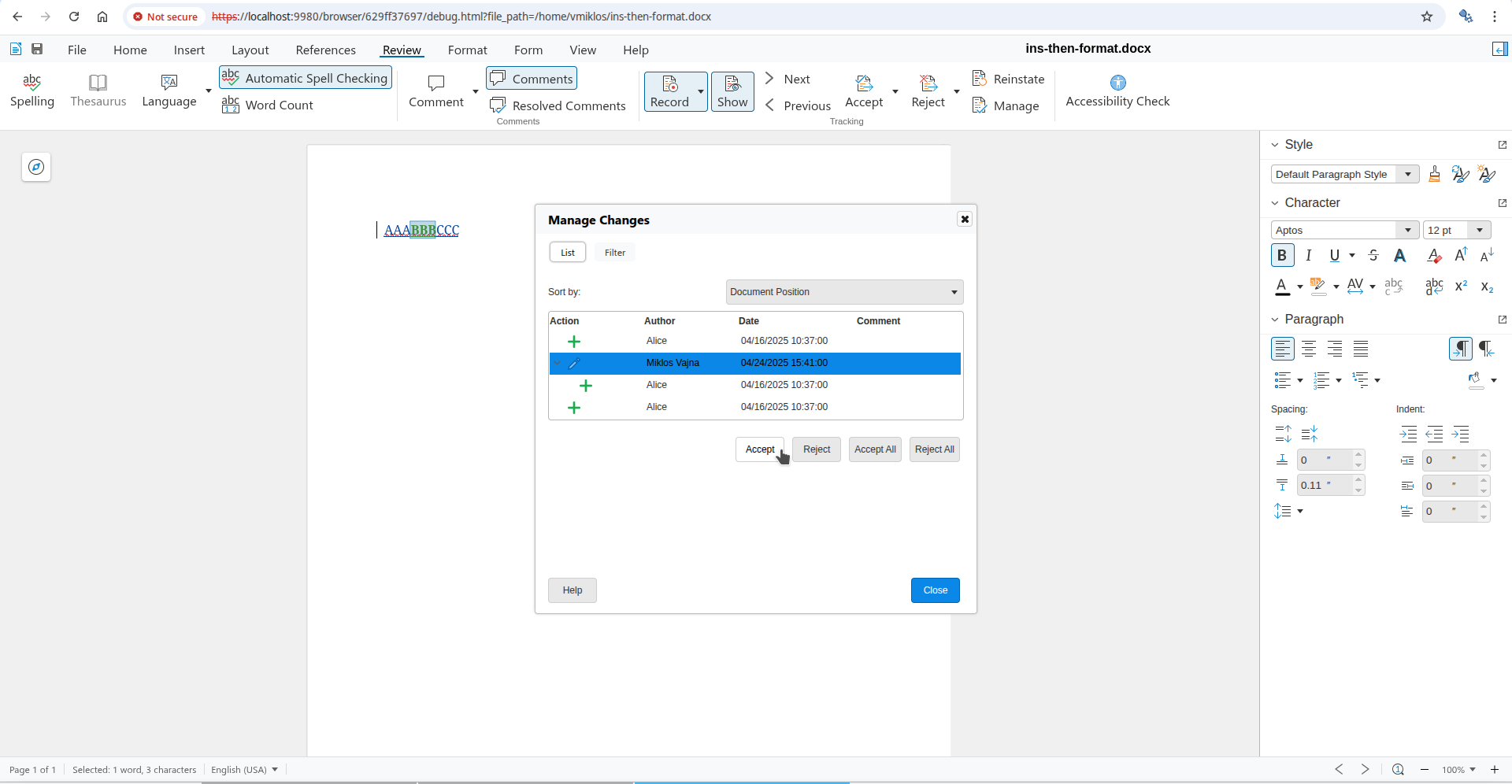
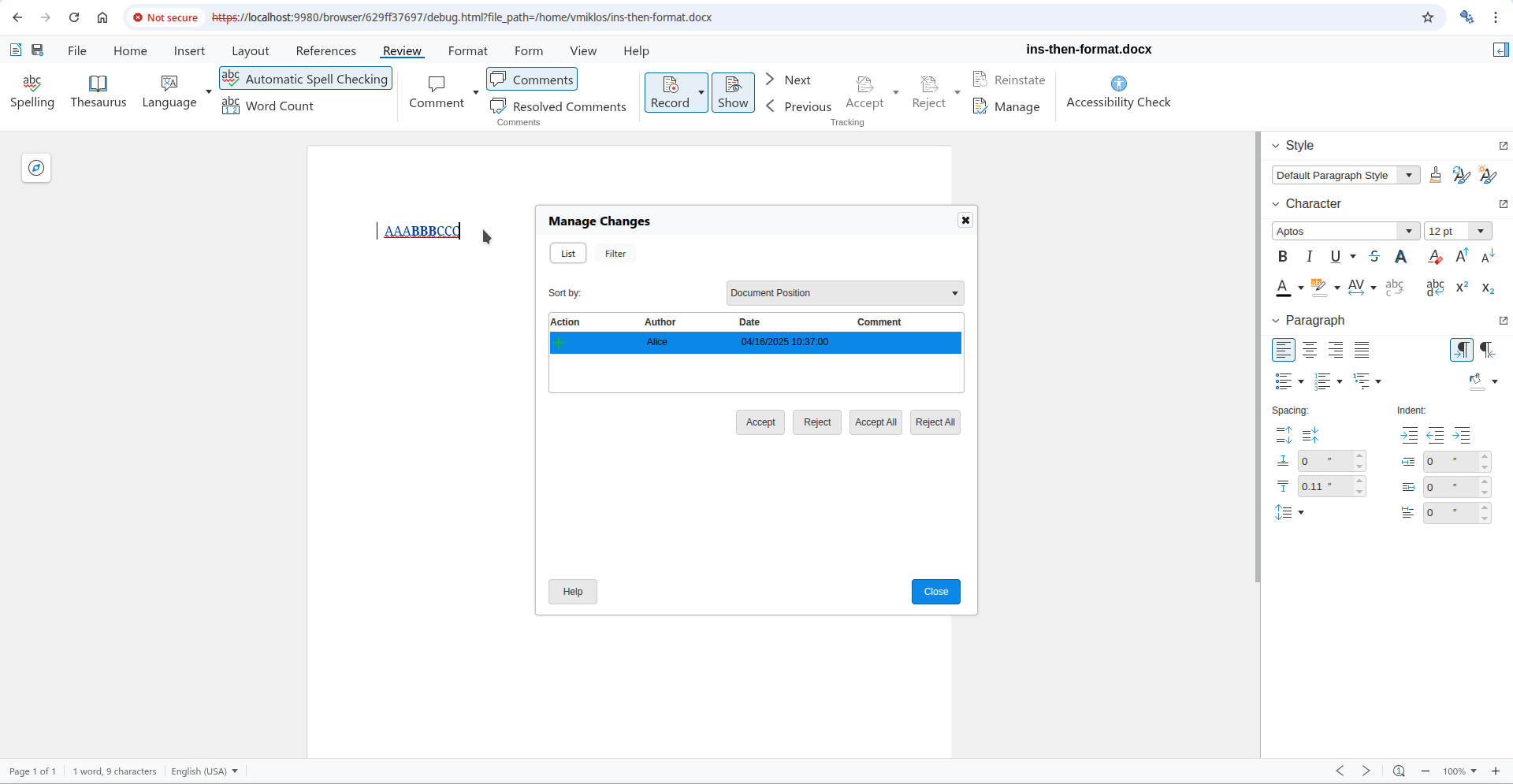
The document from the issue had BBB as bold by Alice:
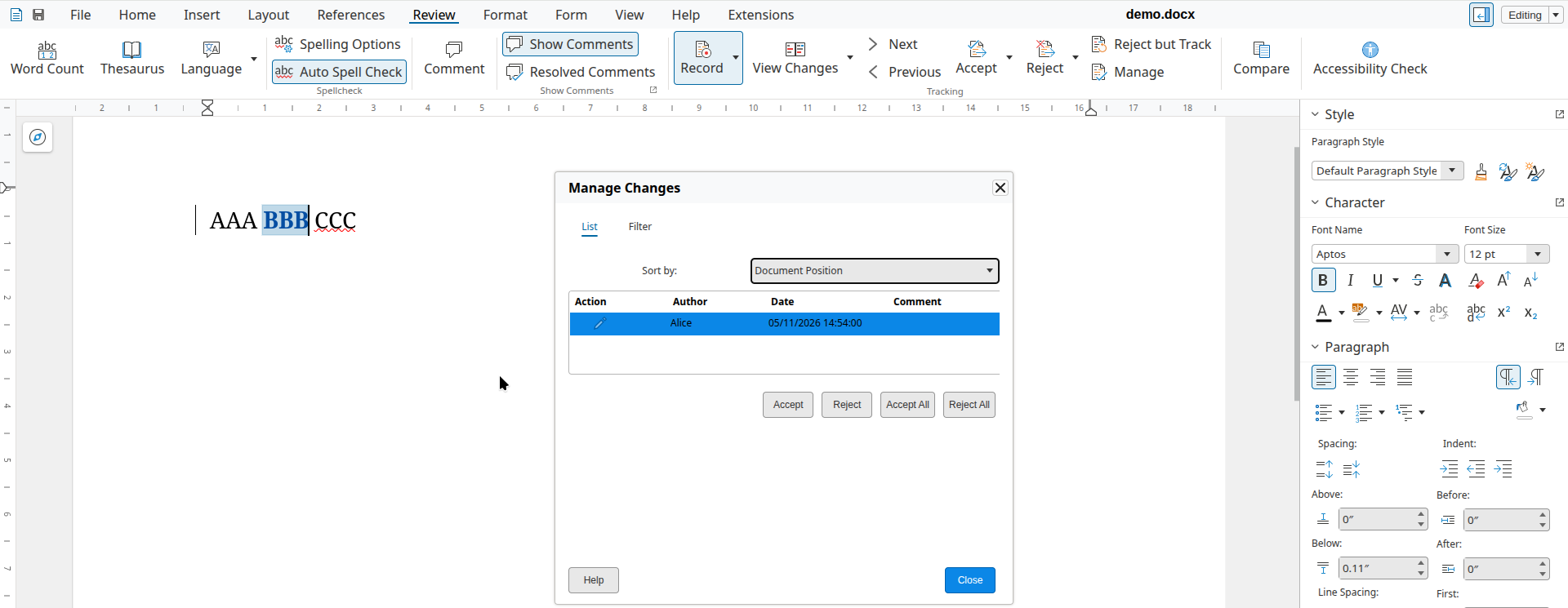
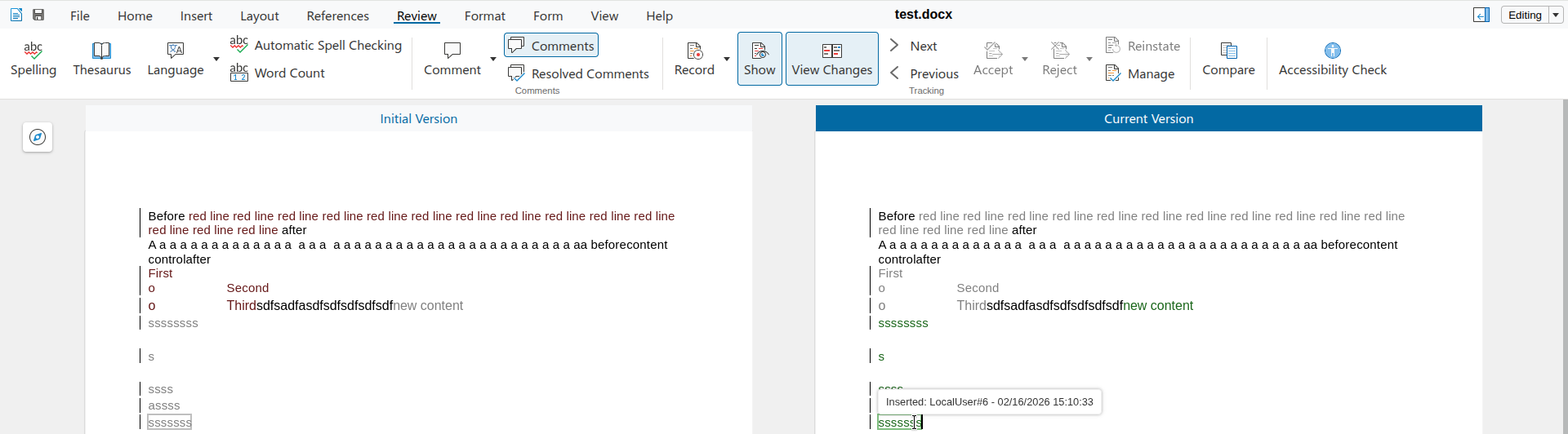
And now once a different editor marks the middle B as italic, additionally, then the formatting on this middle character is now attributed to the new editor:
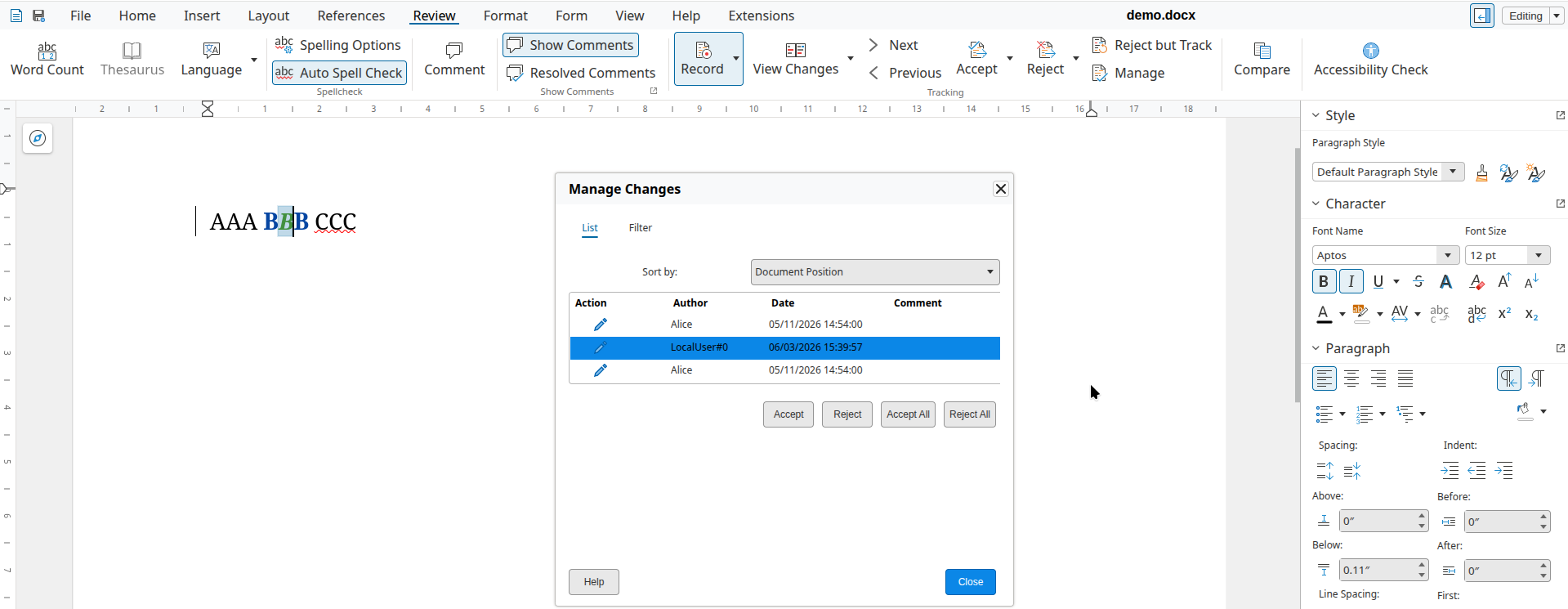
Without the fix, rejection only removed the italics. With the fix, now reject correctly removes both the bold and the italic formatting. Accept is a little bit easier, since we don't need to touch the formatting in the model, just delete the change from the table of changes.
How is this implemented?¶
If you would like to know a bit more about how this works, continue reading... :-)
As usual, the high-level problem was addressed by a series of small changes:
- cool#15451 sw interdependent redlines: fix creating a format on top of format-on-delete
- cool#15749 sw interdependent redlines: fix creating a format on top of format
Want to start using this?¶
You can get a development edition of Collabora Online 25.04 and try it out yourself right now: try the development edition.