Estimated read time: 3 minutes
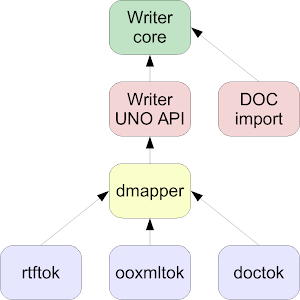
Last year in September we decided to get rid of the writerfilter-based DOC tokenizer, and I volunteered to actually do this. As cleanups in general have a low priority, I only progressed with this slowly, though yesterday I completed it, that’s why I’m writing this post. :-)
Some background: the writerfilter module is responsible for RTF and DOCX import in Writer. As the above picture shows, the currently used DOC import is independent from it, and there was also an other DOC import filter, that was in writerfilter which was disabled at runtime. As I don’t like duplication, I examined the state of the two filters, and the linked minutes mail details how we decided that the old filter will stay, and we’ll get rid of the writerfilter one. It’s just a matter of deleting that code, right? :-) That’s what I thought first. But then I had to realize that the architecture of writerfilter is a bit more complex:
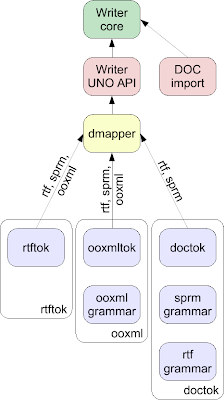
It has the following components:
-
the dmapper (domain mapper), that handles all the nasty complexities of mapping Word concepts to Writer concepts (think of e.g. sections ↔ page styles)
-
one tokenizer for each (RTF, DOCX, DOC) format
The traffic between the tokenizers and dmapper is called tokens. Naturally it’s not enough that tokenizers send and dmapper receives these tokens, they should be defined somewhere as well. And that’s where I realized this work will take a bit more time: instead of having a single token definition, actually the ooxml tokenizer defined its own grammar, and doctok also defined two additional grammars. And of course dmapper had to handle all of that. ;-) Given that OOXML is a superset of the DOC/RTF format, it makes sense to just use the ooxml grammar, and get rid of the other two.
Especially that — by now you probably found this out — if I wanted to kill doctok, I had to kill the sprm and rtf grammars as well. Otherwise just removing doctok would break the RTF and DOCX import as well, as those also used the rtf/sprm grammars.
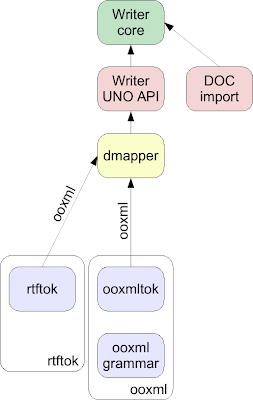
So at the end, the cleaned up architecture now looks like this:
And that has multiple advantages:
-
It removes quite some code: In
libreoffice-4-1, the doctok was 78849 (!) lines of code (well, part of that was XML data, and some scripts generated C++ code from that). -
dmapper now doesn’t have to handle the rtf and sprm grammars anymore, so now there is a single place in dmapper that handles e.g. the italic character property.
-
Smaller writerfilter binary for the end user: even if doctok wasn’t enabled at runtime, it was shipped in the installation set.
-
Hopefully it’s now a bit more easy to understand writerfilter: at least e.g. if you want to look up the place where dmapper handles the character bold ("b") XML tag of OOXML, you don’t have to know that the binary DOC equivalent of that is sprmCFBold, just because we have an unused DOC tokenizer there as well. :-)
-
Given that DOC and RTF formats are a dead end, I think it’s a good thing that in writerfilter now the grammar is OOXML (that keeps introducing new features), rather than some dead format. ;-)