Estimated read time: 1 minutes
I worked on improving document load performance of Microsoft formats in general, and DOC/DOCX in particular in LibreOffice recently. First, thanks to TDF and users that support the foundation by providing donations for funding Collabora to make this possible.
I built on top of the great work of Tomaz, focusing on these secondary, but important formats.
The idea is that if you load an Microsoft binary or OOXML file, it should not be necessary to parse all images at load time, it’s enough to lazy read it when we first render e.g. a Writer page containing that image.
The focus here was documents containing large images. I tested with an Earth photo of size 8000x8000 pixels from NASA, making little modifications to it, so each picture has a different checksum, embedding them into a binary DOC file.
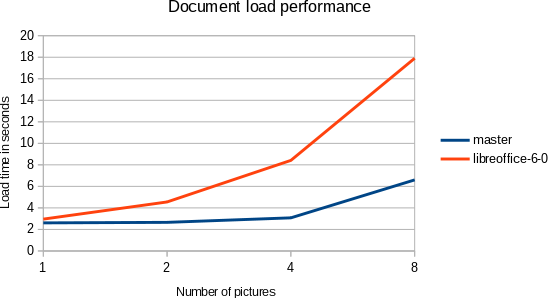
I measured the time from the soffice process startup to rendering the first
page. We defer the work of loading most images now, as you can see on the
chart. In contrast, we used to decompress all images on file import in the
past. This means the new cost for e.g. 4 images is 37% of the original.
All this is available in master (towards LibreOffice 6.1), or you can grab a daily build and try it out right now. :-)