Estimated read time: 3 minutes
Motivation
Padded numbering is a style where you insert 0 characters in front of an otherwise normal (Arabic) numbering, making sure that the result always has at least N characters. Up to now, you had to number your content manually to have this effect, while Word supports this feature.
OOXML supports padding up to 2, 3, 4 and 5 characters. Padding up to 2 characters is the older feature, supported in DOC and RTF as well, so I focused on that piece.
Results so far
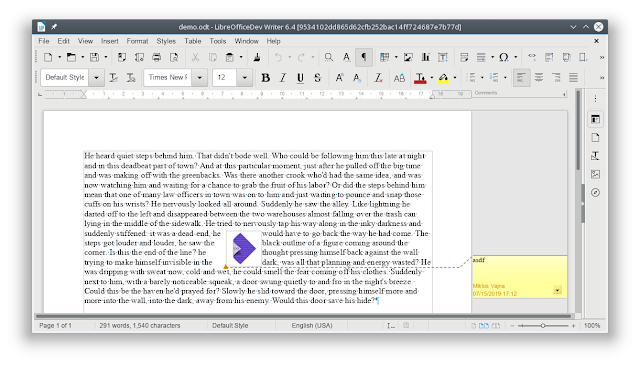
Here is how the current, the baseline and the reference rendering of padded numbering looks like:
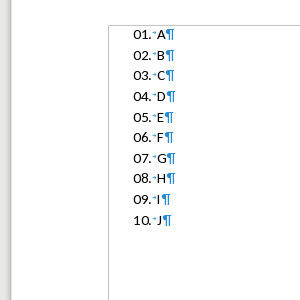


You can see how 0 is inserted before 1..9, but not before 10.
How is this implemented?
If you would like to know a bit more about how this works, continue reading… :-)
-
sw padded numbering: add doc model and UNO API introduced
ARABIC_ZEROexternally andSVX_NUM_ARABIC_ZEROinternally -
sw padded numbering: add layout implements the actual padding in a new
lcl_formatArabicZero()function -
sw padded numbering: add ODF filter decides how this handled for ODF import/export; the spec needs no extension in this case
-
sw padded numbering: add DOCX filter implements OOXML paragraph numbering
-
sw padded numbering: add DOC filter implements [MS-DOC] paragraph numbering
-
sw padded numbering: add RTF export doesn’t touch RTF import, which worked out of the box, due to code sharing with DOCX import
Then I found that footnote numbering needs explicit handling, so added support for padding in that case as well:
-
sw padded numbering: add DOCX footnote export reuses the same markup, just in a different context
-
sw padded numbering: add DOC footnote filter fixed custom number formatting for DOC footnote export in general
Finally I had a little bit of remaining time, so I extended support for the recently added Chicago numbering:
-
sw chicago numbering: add DOCX footnote export builds on top of the existing paragraph numbering support
-
sw chicago numbering: add DOC footnote export only touches footnotes, as this type is not supported for paragraphs
-
sw chicago numbering: add RTF footnote export fixed custom number formatting for RTF footnote export in general
Future work
Padding up to 3, 4 and 5 characters would be possible to do, but it’s DOCX-only, and uses a different markup, planned to be done later.
All this is available in master (towards LibreOffice 7.0), so you can grab a daily build and try it out right now. :-)