Estimated read time: 2 minutes
TL;DR: Import of annotated text ranges from binary DOC format was a problem for quite some time, now it should be as good as it always was in the ODT/DOCX/RTF filter.
Longer version: the import of annotation marks from binary DOC was never perfect. My initial implementation had a somewhat hidden, but important shortcoming, in the form of a "Don’t support ranges affecting multiple SwTxtNode for now." comment. The underlying problem was that annotation marks have a start and end position, and this is described as an offset into the piece table (so the unit was a character position, CP) in the binary DOC format, while in Writer, we work with document model positions (text node and content indexes, SwPosition), and it isn’t trivial to map between these two.
Tamás somewhat improved this homegrown CP → SwPosition mapping code, but was still far from perfect. Here is an example. This is how this demo document looks like now in LibreOffice Writer:

And this is how it looked like before the end of last year:
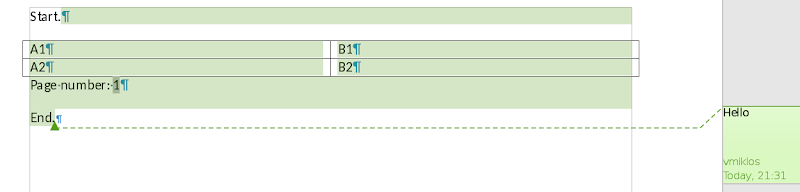
Notice how "Start" is commented and it wasn’t before. Which one is correct? Here is the reference:

The reason is that the document has fields and tables, and the homegrown CP →
SwPosition mapping did not handle this. A much better approach is to handle
the mapping as we do it for bookmarks: even if at the end annotation marks and
bookmarks are entires in sw::mark::MarkManager, it’s possible to set the
start position as a character attribute during import (since mapping the
current CP to the current SwPosition is easy) and when we know both the
start and end, delete the character attribute and turn it into a mark manager
entry. That’s exactly what I’ve done. The first screenshot is the result of 3
changes:
Hopefully this makes LibreOffice not only avoid crashing on such complex annotated contents, but also puts an end to the long story of "annotation marks from binary DOC" problems.
|
Note
|
Just like how C++11 perfect forwarding isn’t perfect — if you think it is, see "Familiarize yourself with perfect forwarding failure cases." in this post of Scoot — the above changes may still not result in a truly perfect import result of DOC annotation marks. But I think the #1 problem in this area is now solved. :-) |