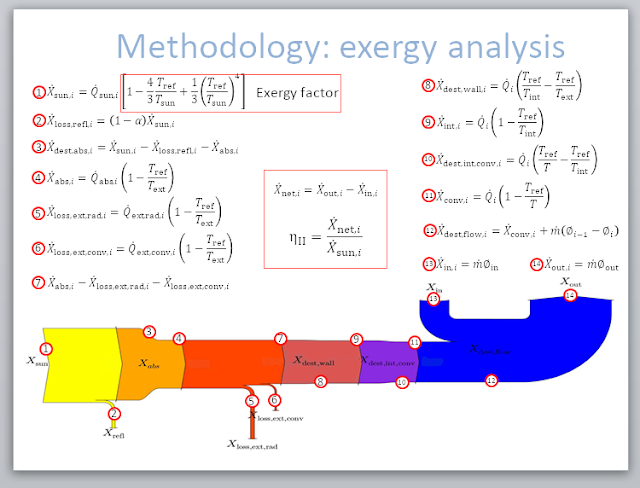
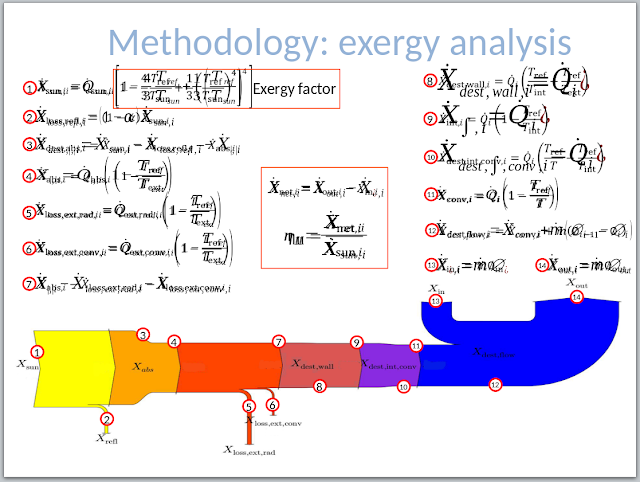
Estimated read time: 2 minutes
Motivation
Padded numbering is a style where you insert 0 characters in front of an otherwise normal (Arabic) numbering, making sure that the result always has at least N characters. Up to now, you had to number your content manually to have this effect, while Word supports this feature.
OOXML supports padding up to 2, 3, 4 and 5 characters. The news is now now it’s possible to not only pad up to 2 characters, but also to any number between 2 and 5.
Results so far
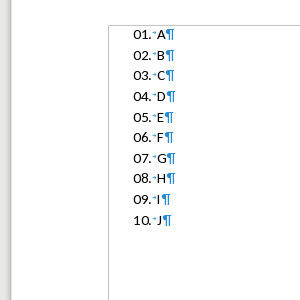
Here is how the current rendering of padded numbering looks like, with a custom prefix and suffix:
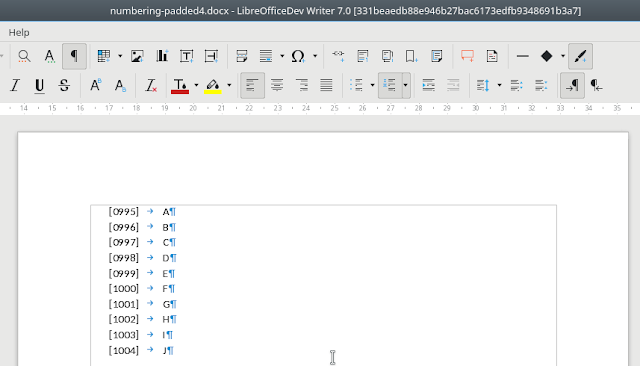
You can see how 0 is inserted before 999, but not before 1000 as this is the pad-to-4 case.
How is this implemented?
If you would like to know a bit more about how this works, continue reading… :-)
-
Padding to a custom number is not something that works in general, because both ODF and OOXML has a separate number format for each padding. So Writer supports the 4 cases Word supports, but (for now) not more.
-
Padding to 3 or more is more complicated than pad to 2, because OOXML has different markups for them.
Here is how the pad-to-2 markup looks like:
<w:numFmt w:val="decimalZero"/>
And here is how you define pad-to-3:
<mc:AlternateContent> <mc:Choice Requires="w14"> <w:numFmt w:val="custom" w:format="001, 002, 003, ..."/> </mc:Choice> <mc:Fallback> <w:numFmt w:val="decimal"/> </mc:Fallback> </mc:AlternateContent>
-
This required taking the
w14branch when we hit such a conditional, we used to read the fallback branch previously. -
This required mapping the data of the
<w:numFmt>XML element not to an enumeration value, but to a pair of objects: the numbering format’s value and format.
The rest was reasonably straightforward, since the actual padding implementation just had to be generalized.
Want to start using this?
You can get a snapshot / demo of Collabora Office and try it out yourself right now: try unstable snapshot. Collabora is a major contributor to LibreOffice and all of this work will be available in TDF’s next release too (7.0).