Estimated read time: 1 minutes
The problem
Years ago I posted about work to attach comments to
text ranges. This improved compatibility with Word greatly, but it was always a piece of text that
was commented, never frames. If you just selected a frame and tried to comment by selecting the menu
entry or the Ctrl-Alt-C shortcut, nothing happened, because frame selection did not interpret
comment insertion.
Result
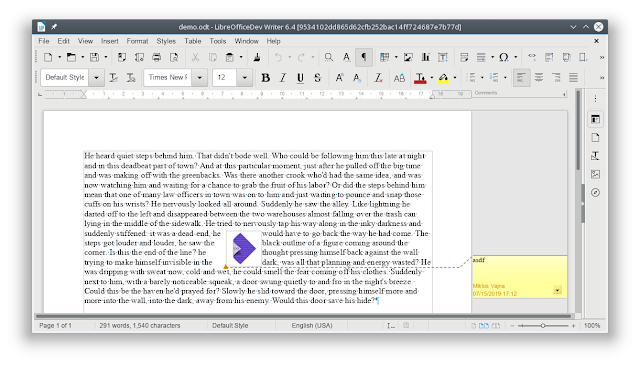
Examples for frames are images or charts. This needs explicit handling, so at the moment the at-char and as-char anchor types are supported, and you can simply insert the comment to a frame once the frame is selected. This works in both desktop Writer and Online.
Want to start using this?
You can get a snapshot / demo of Collabora Office and try it out yourself right now: try unstable snapshot. Collabora is a major contributor to LibreOffice and all of this work will be available in TDF’s next release too (6.4).