Estimated read time: 2 minutes
I recently dived into the SmartArt support of LibreOffice, which is the component responsible for displaying complex diagrams from PPTX, especially in case only document model and the layout constraints are given, not a pre-rendered result.
The problem
There are several ones. :-) If you are just interested in high quality viewing of PPTX files, then your problem started with PowerPoint 2007 not writing a pre-rendered drawingML markup of the diagram to the files, only PowerPoint 2010 started behaving like this. Additionally, if a diagram is not edited, then re-saving with PowerPoint 2010 doesn’t seem to generate the drawingML markup, either. This means that data + constraints cases are quite frequent even today.
Also, one day Impress should be able to actually edit these SmartArts as well, so having the knowledge how to lay out SmartArt (even if it’s import-time-only at the moment) is a good thing.
Results so far
I always write cppunit tests when I work on filter code (in this case OOXML), so far all fixes were visible in just two test files: smartart-vertial-box-list.pptx and vertical-bracket-list.pptx.
Here is how the baseline, the current and the reference rendering of these test documents look like:
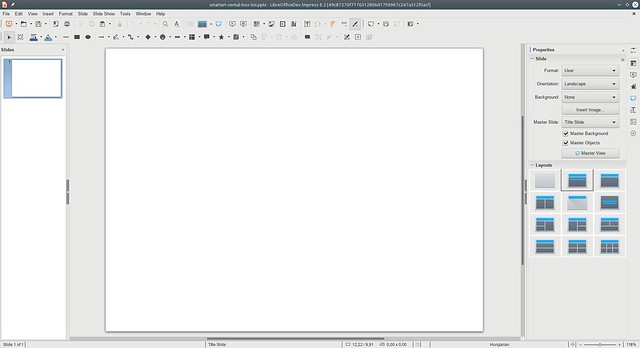
smartart-vertial-box-list.pptx, baseline
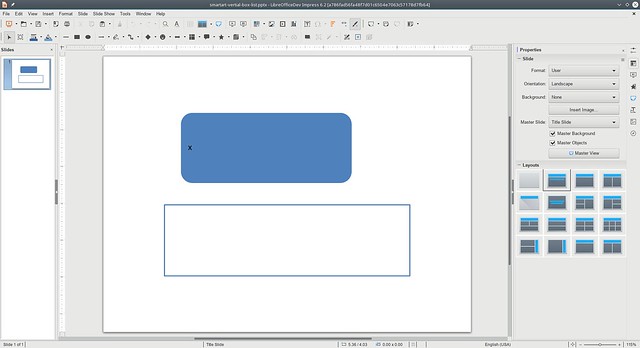
smartart-vertial-box-list.pptx, current

smartart-vertial-box-list.pptx, reference
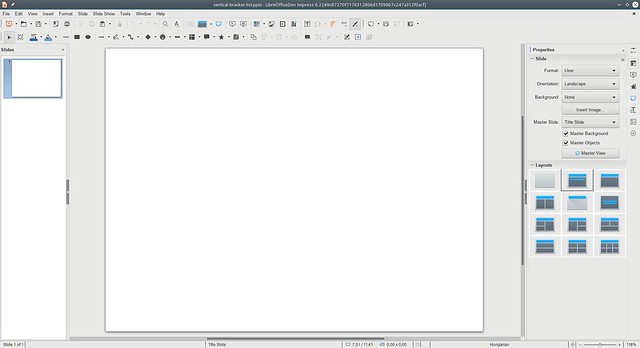
vertical-bracket-list.pptx, baseline
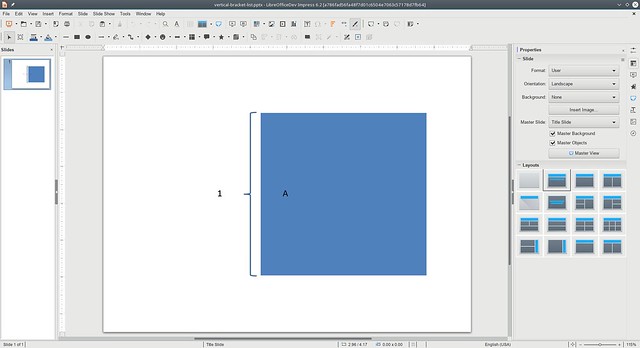
vertical-bracket-list.pptx, current
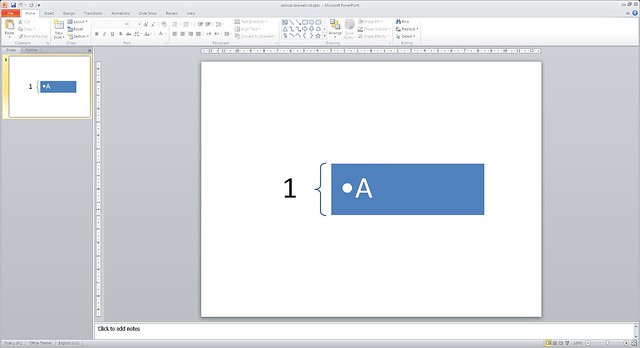
vertical-bracket-list.pptx, reference
In terms of code commits, the fixes are split into several ones:
Clearly the results are not perfect yet, but in both cases nothing was visible, and now all text is readable, so we’re moving in the right direction!
All this is available in master (towards LibreOffice 6.2), so you can grab a daily build and try it out right now. :-)