Estimated read time: 2 minutes
The problem

The result
The first topic is that whenever I looked at supporting the new bottom-to-top, left-to-right direction, I always first checked if the more common top-to-bottom, right-to-left direction is working or not (this is used for e.g. Japanese rotated text). Turns out that Writer text frames were not exported to drawingML (part of DOCX), so I fixed that.
Similarly, there is the older shape markup in DOCX: VML. The tbRl direction from that was broken, too, now working nicely.
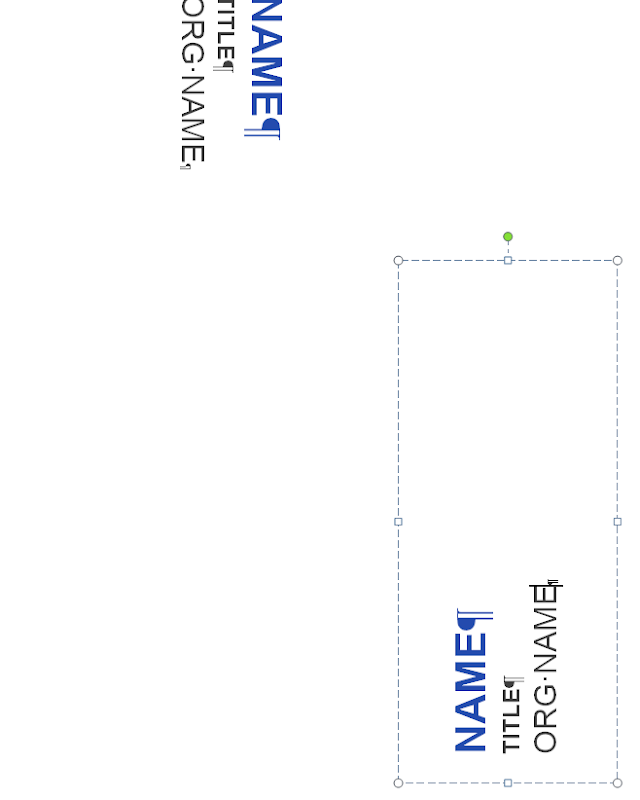
Then I could actually look at the btLr import from VML, which is now correct.
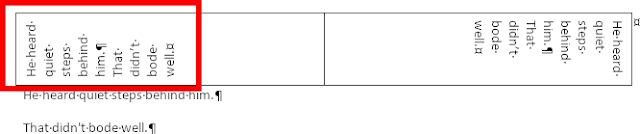
One of the motivations for this work was to get rid of the old, miserable hack where we did
character-level rotation during import (which falls apart for multi-paragraph text). If the import
mapping in itself is not painful enough, we had to undo the effect of this import hack at export
time. When I could remove the last usage of this dreaded checkFrameBtlr() function in the export
code, I mentally did a little dance. ;-)
Back to btLR fixing, exporting Writer text frames to DOCX is not interesting when you do DOCX editing, but it’s very much relevant when you do ODT → DOCX conversion. And the btLr case was of course not handled, fixed now.
RTF was broken in 4 different ways: import and export was broken for the btLr and the tbRl cases for text frames.
The last thing was the binary DOC export, where btLr text frames were not handled.
With these sorted out, I think the topic of table cells and shapes / text frames are now supported reasonably well. ODF could do the btLr writing direction for sections and pages as well, but I don’t see that as a priority. And hey, Word doesn’t support them, either. :-)
Want to start using this?
You can get a snapshot / demo of Collabora Office and try it out yourself right now: try unstable snapshot. Collabora is a major contributor to LibreOffice and all of this work will be available in TDF’s next release, too (6.4).