Estimated read time: 1 minutes
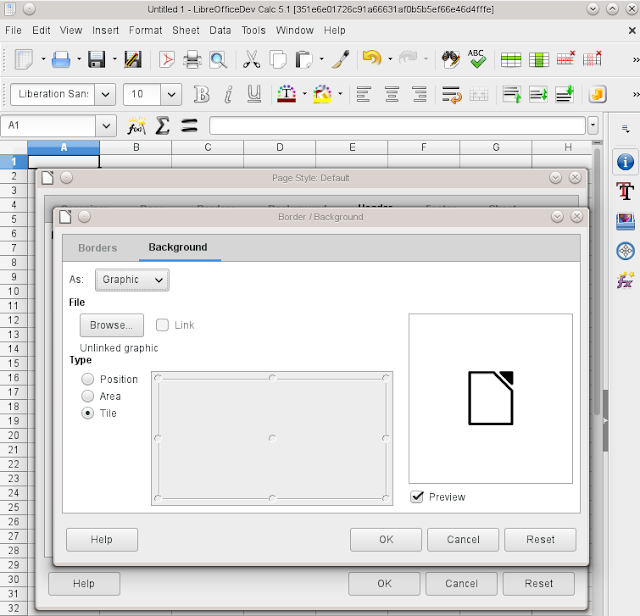
I think this is my first Calc bugfix. :-) The problem I wanted to fix is that while LibreOffice 4.4 learned advanced fill attributes (gradients, hatches, etc) for page headers / footers in Writer, this broke the saving of simple graphic header backgrounds in Calc. Seeing that no-one stepped up to fix this, I tried to do this myself — and luckily the problem was in the ODF export filter, which is much more familiar to me, compared to Calc core.
Part of that larger feature was changes to the ODF filter, and the bug was exactly about touching shared ODF filter code to please Writer without testing other LibreOffice applications.
The actual problem was overlapping constants: as in multiple constants had the same numeric value. Such issues are sometimes hard to track down, in this case it wasn’t that hard: the context filter that tried to make sure we don’t write duplicated XML attributes removed the background property when it tried to guard header repeat offsets.
Given that this affected the LibreOffice 4.4 and 5.0 series, both branches got a backport of the commit, and so the next release from those lines will have the fix.