Estimated read time: 4 minutes
As someone who usually hacks on LibreOffice, external import filters produced by the Document Liberation Project cut both ways: they are great, as they deal with obscure formats and we get them for free, OTOH hacking such code is more complex than the usual LO code. I recently contributed a few patches to libvisio and libodfgen, but before I was able to do actual code changes, I had to set up a number of repositories and configure them to talk to each other — this post describes one possible setup that suited my needs.
Building blocks
DLP’s central project is librevenge and everything builds on top of that, either by calling it or called by it. In case the task is to turn VSDX files into ODG ones, it looks like this:
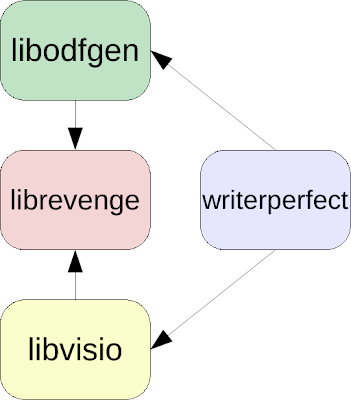
libvisio can build a librevenge document model from Visio files (more on the various librevenge-based libraries here), libodfgen can generate ODF output from such document models (one other possibility would be e.g. libepubgen), and the writerperfect module provides kind of a controller for the remaining modules, e.g. for our purpose, a vsd2odg binary.
Alternatives considered
One possibility is to build LibreOffice, use --with-system-libvisio and
similar switches, then clone the repos, install them system-wide (possibly
with your modifications), and then you can test your changes just with
building the various libs, without changing your LO build (more
here).
The drawback is that this way you pollute your system with unstable versions
of those libs.
An other possibility is to build LibreOffice as usual, and then use the external libraries patching mechanism to hack on the code. The drawback is that you have to work without git on the code, and also you can only work with a released version.
The pkg-config approach
So here is what I did to avoid the above mentioned drawbacks: all DLP projects use pkg-config to find the required libraries, so you can configure them in a way that allows building as a user, avoid installing them at all, and still execute vsd2odg using the libs with your changes. Here is how to do it:
-
librevenge:
git clone git://git.code.sf.net/p/libwpd/librevenge
cd librevenge
./autogen.sh
./configure --enable-debug
make
-
libvisio:
git clone git://gerrit.libreoffice.org/libvisio
cd libvisio
./autogen.sh
./configure REVENGE_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-0.0" REVENGE_GENERATORS_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_GENERATORS_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-generators-0.0" REVENGE_STREAM_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_STREAM_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-stream-0.0" --enable-debug --enable-werror
make
-
libodfgen:
git clone git://git.code.sf.net/p/libwpd/libodfgen
cd libodfgen
./autogen.sh
./configure REVENGE_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-0.0" REVENGE_STREAM_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_STREAM_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-stream-0.0" --enable-debug
make
-
writerperfect:
git clone git://git.code.sf.net/p/libwpd/writerperfect
cd writerperfect
./autogen.sh
./configure REVENGE_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-0.0" REVENGE_STREAM_CFLAGS="-I/home/vmiklos/git/libreoffice/librevenge/inc" REVENGE_STREAM_LIBS="-L/home/vmiklos/git/libreoffice/librevenge/src/lib/.libs/ -lrevenge-stream-0.0" ODFGEN_CFLAGS="-I/home/vmiklos/git/libreoffice/libodfgen/inc" ODFGEN_LIBS="-L/home/vmiklos/git/libreoffice/libodfgen/src/.libs -lodfgen-0.1 -lrevenge-0.0 -lrevenge-stream-0.0" VISIO_CFLAGS="-I/home/vmiklos/git/libreoffice/libvisio/inc" VISIO_LIBS="-L/home/vmiklos/git/libreoffice/libvisio/src/lib/.libs -lvisio-0.1 -lrevenge-0.0" --enable-debug --with-libvisio
Of course, replace /home/vmiklos/git/libreoffice/ with any other directory
you like, just be consistent. ;-)
Now you can hack on any of these libraries, you just need to build your changes, and then vsd2odg will produce a flat ODG that you can quickly test with any ODF processor, like LibreOffice. One remaining trick (in case you’re not an autotools expert) is that vsd2odg is a libtool shell script, not a binary. If you still want to run the underlying binary in gdb, here is how you can do that:
libtool --mode=execute gdb --args vsd2odg /home/vmiklos/git/libreoffice/test.vsdx
In case the above considered two alternatives are not sufficient for your purposes, then I hope you find this setup useful. ;-)