Estimated read time: 1 minutes

Last Friday I gave a Text layout performance lightning talk at LibreOffice Conference 2018. Click on the image to get the hybrid PDF slides!
Estimated read time: 1 minutes
Last Friday I gave a Text layout performance lightning talk at LibreOffice Conference 2018. Click on the image to get the hybrid PDF slides!
Estimated read time: 1 minutes

Earlier today I gave an Editing ReqIF-XHTML fragments with Writer talk at LibreOffice Conference 2018. The room was well-crowded — perhaps because the previous talk was about OOXML interoperability. ;-)
I expect quite some other slides will be available on Planet, don’t miss them.
Estimated read time: 1 minutes
I created a toy project to experiment with a few technologies I wanted to try out (cmake, googletest, xmlsec outside LibreOffice, libzip and AppVeyor). The result is a tool with a similar interface as pdfsig from poppler (for PDF files), just for ODF: a cmdline executable to verify the digital signature(s) in an ODF document.
The source code now has CI on Linux and Windows, so perhaps in a shape that is interesting for others to have a look as well. And if not, then no problem, it was interesting to put together these building blocks and see them working as expected. :-)
Estimated read time: 1 minutes
I used to have a hackish setup to trigger address book in the form of code completion from vim, when mutt starts it. I recently migrated the last part of it from python2, so it’s now in a relatively consistent state. On a boring flight trip I finally got around to summarize how it works, perhaps it’s useful to someone else as well. :-)
By multiple sources, I mean Google Contacts for my private account, and LDAP for work-related accounts. I have one script for each to have a local backup:
google/contacts/backup
backs up Google Contacts to $HOME/.google-contacts/
ldap/contacts/backup
backs up from an LDAP source to $HOME/.ldap-contacts/
Then comes
mutt/contacts/search,
which can read these backups from $HOME/.mutt/contacts/ (you can create
symlinks to decide which backup should be included in the search results).
The rest is just a short
search.vim
that integrates the search script into vim, so when mutt starts it with
ft=mail, the search script is invoked when you start typing and you press
Ctrl-X Ctrl-O (trigger code completion).
And that’s it, I can start typing mails to friends and customers even without network connectivity, without manually maintaining an own address book just for mutt!
Estimated read time: 2 minutes
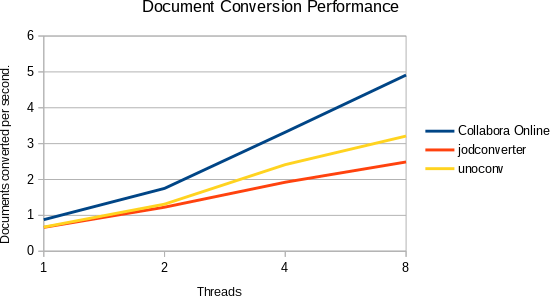
Background: I was benchmarking Online vs jodconverter vs unoconv the other day
for Collabora’s document
conversion page. One problem with measuring unoconv performance was that it
provided no ways to run multiple unoconv processes in parallel, while the
underlying soffice binary obviously allows this.
So while unoconv is not capable of launching the soffice process in a chroot
(improves security), nor is capable of forking an already pre-initialized
soffice process (improves performance, both are things Online can do for you),
there is no real reason why you should not be able to run multiple unoconv
processes in parallel. The previously mentioned benchmarking would be quite
unfair if even this kind of multiprocessing would be ignored, but unoconv had
no way to specify a custom user profile, which has to be different for each
soffice process.
So I filed a GitHub pull request on 1st Jun, and finally it was merged on 10th Aug.
Here is how you can use it for example:
unoconv --user-profile /tmp/tmpf_yreswi -f pdf --port 2002 test.txt|
Note
|
It’s your responsibility to give --port a unique value, but that’s not
too hard: if you use a thread pool to launch the unoconv processes, then you
can add the thread index to a base port and that will give you a unique port. |
So this is available in unoconv master (towards unoconv 0.8.2+1), you can grab the sources from git and try it out right now. :-)
Estimated read time: 3 minutes
The UNO API of Draw allows you to build quite complex and custom shapes, but you may want to export the rendered result to a bitmap for testing purposes, so you can assert that the actual result matches a reference one.
One problem in this area is anti-aliasing, which can easily differ between machines. Given that normally aliased rendering is ugly, there is now a way to enable AA, but disable it just during a single invocation of the PNG exporter.
The above picture shows how the AA result looks like. You could write a Basic macro like this to trigger the PNG export from Draw:
xExporter = createUnoService("com.sun.star.drawing.GraphicExportFilter") xExporter.SetSourceDocument(ThisComponent.DrawPages(0)) Dim aArgs(1) As new com.sun.star.beans.PropertyValue aArgs(0).Name = "URL" aArgs(0).Value = "file:///tmp/debug/aa.png" aArgs(1).Name = "MediaType" aArgs(1).Value = "image/png" xExporter.filter(aArgs())
Let’s see how it looks like if you turn AA off:

You just need to specify a new Antialiasing key under FilterData:
Dim aFilterData(0) As new com.sun.star.beans.PropertyValue aFilterData(0).Name = "AntiAliasing" aFilterData(0).Value = False xExporter = createUnoService("com.sun.star.drawing.GraphicExportFilter") xExporter.SetSourceDocument(ThisComponent.DrawPages(0)) Dim aArgs(2) As new com.sun.star.beans.PropertyValue aArgs(0).Name = "URL" aArgs(0).Value = "file:///tmp/debug/non-aa.png" aArgs(1).Name = "FilterData" aArgs(1).Value = aFilterData() aArgs(2).Name = "MediaType" aArgs(2).Value = "image/png" xExporter.filter(aArgs())
You can imagine which rendering result is easier to debug when the reference and the actual bitmap doesn’t match. ;-)
|
Note
|
This feature is available for other bitmap formats as well, PNG is only an example. |
In most cases you don’t really need a default character style: if you’re fine with a default, then the default paragraph style should be enough for your needs. In general, paragraph styles can contain character properties, so if the default is fine for you, you just don’t set a character style.
However, there is an exception to all rules. If you want to reset the current
character style, it makes sense to just set the CharStyleName property to a
default value, especially since this works with paragraph styles already.
Now you can write C++ code like this (see SwUnoWriter::testDefaultCharStyle() for a full example):
xCursorProps->setPropertyValue("CharStyleName", uno::makeAny(OUString("Standard")));
And it’ll be handled as Default Style in English builds, or their localized
versions in a non-English UI.
All this is available in master (towards LibreOffice 6.2), or you can grab a daily build and try it out right now. :-)
Estimated read time: 2 minutes
I wrote about ECDSA handling in LibreOffice last year, back then the target was to be able to verify signatures using the ECDSA algorithm on Linux.
Lots of things happened since then, this post is meant to summarize those improvements. My personal motivation is that Hungarian eID cards come with a gov-trusted ECDSA (x509) cert, so handling those in LibreOffice would be nice. My goals were:
platforms: handling Windows as well, not only Linux/macOS
operations: handling signing as well, not only verification
formats: cover all of ODF, OOXML and PDF
Let’s see what has happened:
Linux, ODF, sign: we had hardcoded RSA algorithm when generating a signature, now we infer the sign algorithm from the signing cert algorithm (commit)
Linux, OOXML, sign: same problem with hardcoded RSA (commit)
Windows, PDF, sign: the certificate chooser had to be ported to from CryptoAPI to CNG (commit)
Windows, ODF, verify / sign: this was the largest problem, this required a whole new libxmlsec backend (interface, implementation, all in C90) and also required conditionally using that new backend in LibreOffice (commit)
Windows, OOXML, sign: this was almost functional, except that the UI recently regressed, now fixed (commit)
Finally now that everything is ported on Windows to use CNG, I could enable it by default yesterday.
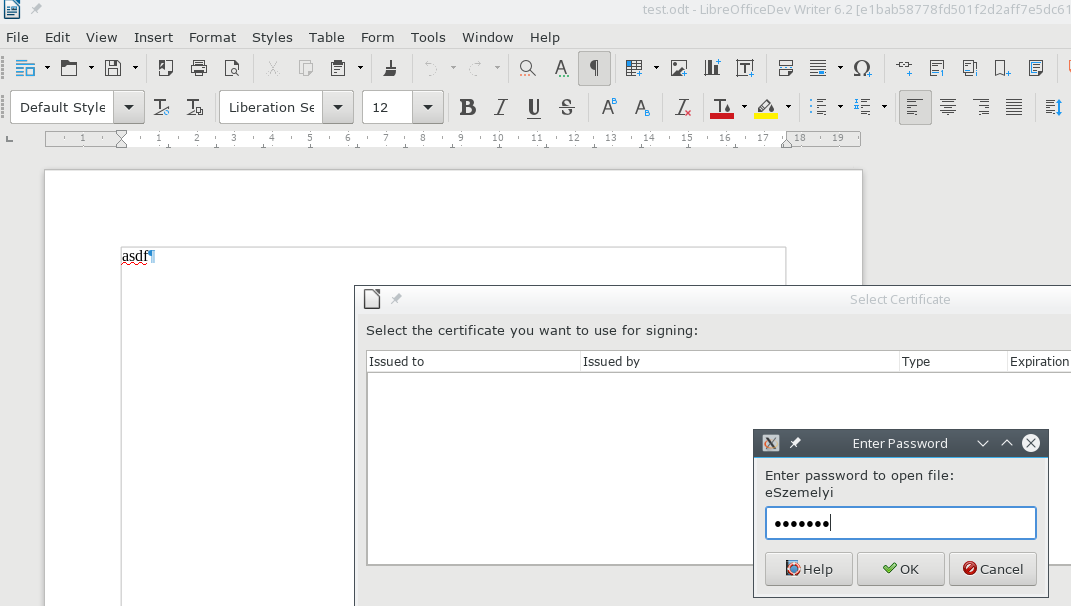
I could test hardware-based signing after this, which was fine out of the box on both platforms. Some screenshots:
Linux:
Windows:
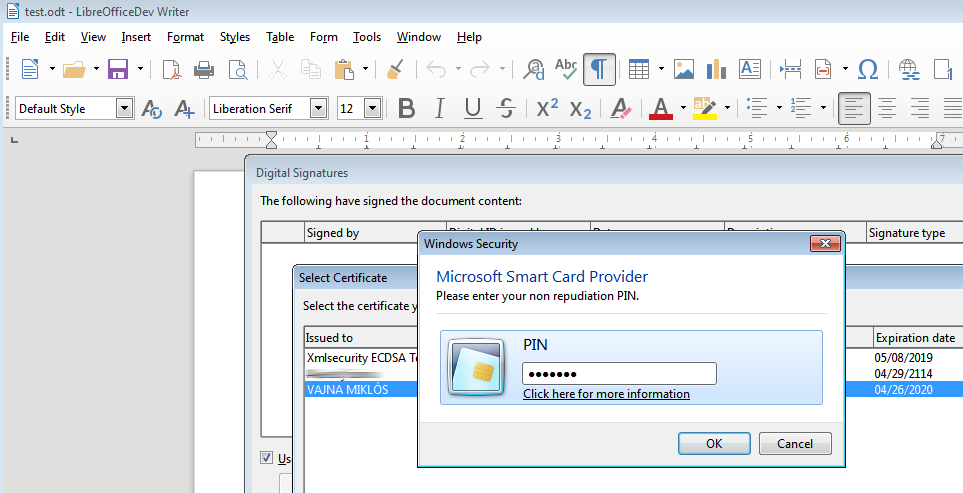
(There is no reason why this would not work on macOS, but I did not test that.)
Thanks Gabor Kelemen who helped me to get a sane card reader that has reasonable driver support on Linux.
All this is available in master (towards LibreOffice 6.2), or you can grab a daily build and try it out right now. :-)
Estimated read time: 2 minutes
I worked on a small feature to use Writer as an editor for the XHTML fragments inside Requirements Interchange Format (ReqIF) files. First, thanks to Vector for funding Collabora to make this possible.
Writer already supported XHTML import and export before (see my previous post) as a special mode of the HTML filter, this work builds on top of that. The main speciality around XHTML as used for fragments inside a ReqIF file is embedded objects.
The special mode to opt-in for ReqIF-XHTML behavior can actived like this:
during import: --infilter="HTML (StarWriter):xhtmlns=reqif-xhtml"
during export: -convert-to "xhtml:HTML (StarWriter):xhtmlns=reqif-xhtml"
Three different cases are handled:
Image with native data we don’t understand and just preserve.
Image with OLE2 data, which we hand out to external applications (at least on Windows). On the above video this is an embedded PPSX file, handled by PowerPoint.
Image with ODF data, which we handle internally. This is a Draw document on the above video.
Regarding how it works, the import is a series of unwrapping containers till you get to the real data and the export is the opposite of this. Here are the layers:
Larger ReqIF files have the .reqifz extension, and are ZIP files
containing an XML file, having the XHTML fragments. This is not relevant for
this post, as Writer assumes that extracting the XHTML fragment from ReqIF is
done before you load the content into Writer.
XHTML always has a PNG image for the object, and optionally it has RTF as native data for the object.
The RTF file is a fragment, containing just an embedded OLE1 container.
The OLE1 container is just a wrapper around the real OLE2 container.
The OLE2 container either has the data directly or MSO has a convention on how to include OOXML files in it (see the PPSX example above), and we handle that.
On export we do the opposite: save the file, put it into OLE2, then into OLE1, then into RTF, finally into XHTML.
There is no specification on how to put ODF files into OLE2, so I extracted the relevant code from LibreOffice’s binary MSO filters and now the Writer HTML filter uses that as well. This avoids code duplication and also could avoid inventing some new markup this way.
All this is available in master (towards LibreOffice 6.2), or you can grab a daily build and try it out right now. :-)
Estimated read time: 1 minutes
I worked on improving document load performance of Microsoft formats in general, and DOC/DOCX in particular in LibreOffice recently. First, thanks to TDF and users that support the foundation by providing donations for funding Collabora to make this possible.
I built on top of the great work of Tomaz, focusing on these secondary, but important formats.
The idea is that if you load an Microsoft binary or OOXML file, it should not be necessary to parse all images at load time, it’s enough to lazy read it when we first render e.g. a Writer page containing that image.
The focus here was documents containing large images. I tested with an Earth photo of size 8000x8000 pixels from NASA, making little modifications to it, so each picture has a different checksum, embedding them into a binary DOC file.
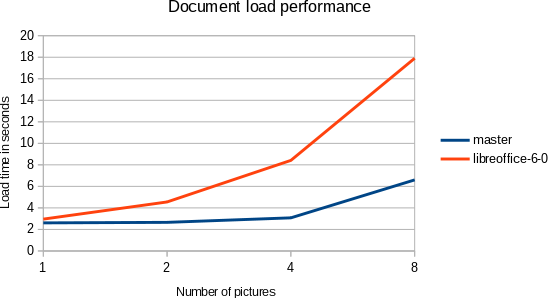
I measured the time from the soffice process startup to rendering the first
page. We defer the work of loading most images now, as you can see on the
chart. In contrast, we used to decompress all images on file import in the
past. This means the new cost for e.g. 4 images is 37% of the original.
All this is available in master (towards LibreOffice 6.1), or you can grab a daily build and try it out right now. :-)
Estimated read time: 2 minutes

(via Sweet5hark)
I arrived home from Hamburg yesterday where I participated in the LibreOffice hackfest over the weekend as a mentor. First, thanks to The Document Foundation — and all the donors for funding Collabora to make this possible.
There were a few topics I mentored:
Patrick was interested fixing tdf#116486, which required some background knowledge on the Writer document model and layout, so we explored the relevant details together towards providing an actual patch for the bug.
Nithin wanted to fix tdf#112384, which turned out to be an ideal task for a hackfest. On one hand, the scope is limited so that you can implement this mini-feature over a weekened. On the other hand, it required touching various parts of Writer (UI, document model, UNO API, ODF filter), so it allowed seeing the process of adding a new feature. The patch is merged to master.
Linus looked for a task that is relatively easy, still useful, we looked at tdf#42949, and he identified and removed a number of unused includes himself. This should especially help with slow incremental builds. Again, the patch is already in master.
Zdeněk (raal) wanted to write a uitest for tdf#106280 so we were figuring out together how to select images from pyuno and how to avoid using graphic URLs in uitests in general.
The full list of achievements is on the wiki, if you were at the hackfest and you did not contribute to that section, please write a line about what did you hack on. :-)
Finally, thanks for the organizers and the sponsors of the hackfest, it was a really great event!
