Estimated read time: 3 minutes
In from selections to graphic handling, I wrote about how we let the LibreOffice Android app select, resize and move images and shapes. Now that we have all type of selections (at least for Writer) in this TDF-funded project, let’s do some formatting! The example implemented by Jan Holesovsky here is to mark the text bold, but you can imagine that using the same technique a number of other character or paragraph properties could be set the same way with little work.
Here is how it works:
-
When you click on toolbar buttons on the desktop UI, so-called UNO commands are invoked, bold is
.uno:Bold. -
This command is generated by the native Android UI as well, and passed to the
lok::Document::postUnoCommand()LOK API. -
Then the LOK implementation uses the recently introduced
comphelper::dispatchCommand()internal API to actually execute it. -
In all applications (Writer, Calc, Draw and Impress) this command is then evaluated on the current selection: so if you have a cursor position, then from now on the new characters will be bold — or if you have a selection, then that will be adjusted. The point is that this works exactly how it happens with the desktop UI, reusing the same code.
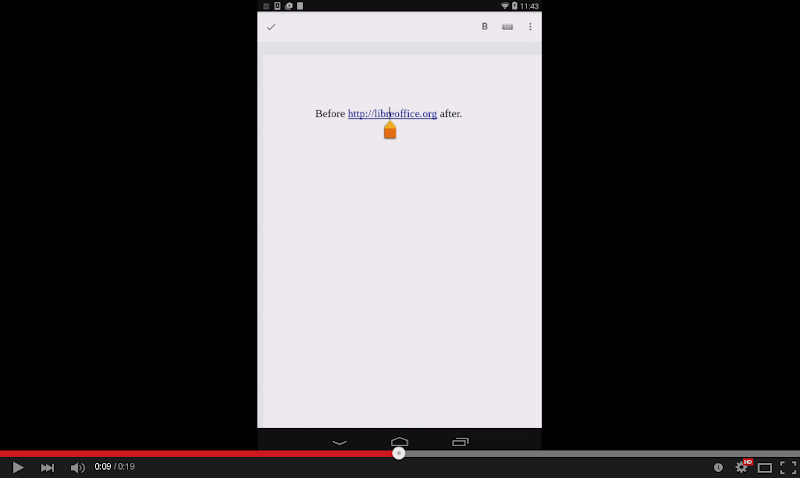
If you are interested how this looks like, here is a demo (click on the image to see the video):
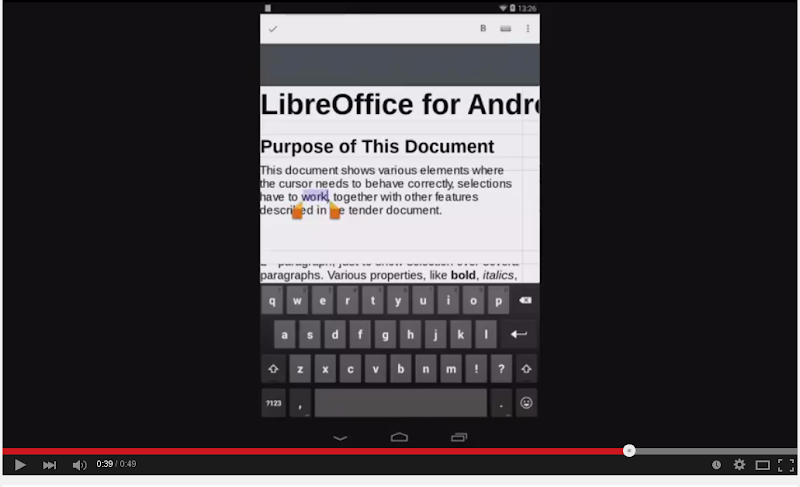
Notice that Calc also gained a number of new features, like cell selection, blinking cursor, text selection with much help from Henry Castro.
Now that Writer is nearly functional for the basic editing features that would be good to see in all four applications, time to look at what’s new in Impress-land!
To bring Impress in line with Writer, we implemented the followings with Tomaž Vajngerl:
-
shape text now has a blinking cursor with a cursor handle that can be dragged
-
long push on a word results in a shape text selection with selection handles that can be dragged
-
it’s now possible to resize shapes
-
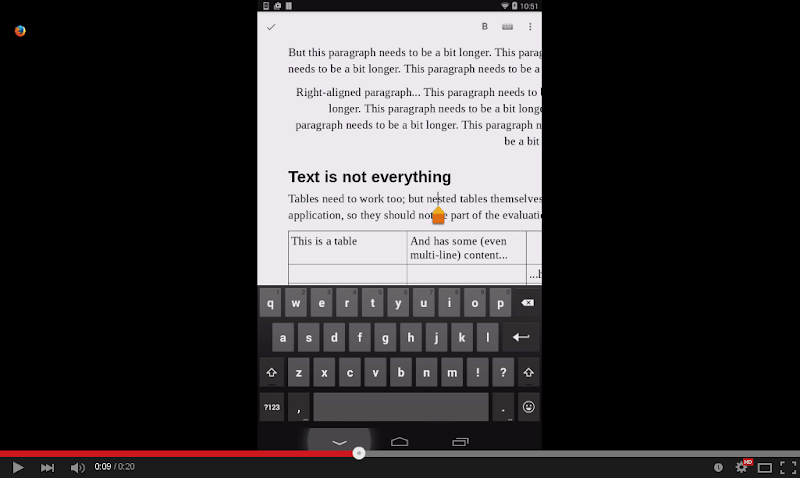
Impress table selections can be created in two ways: either by long pushing on an empty Impress table cell, or by long pushing on shape text inside a cell, and then turning that shape text selection into a table one.
-
it’s possible to tap on a selected shape without text to add text to it.
Here is a demo to show this in action:
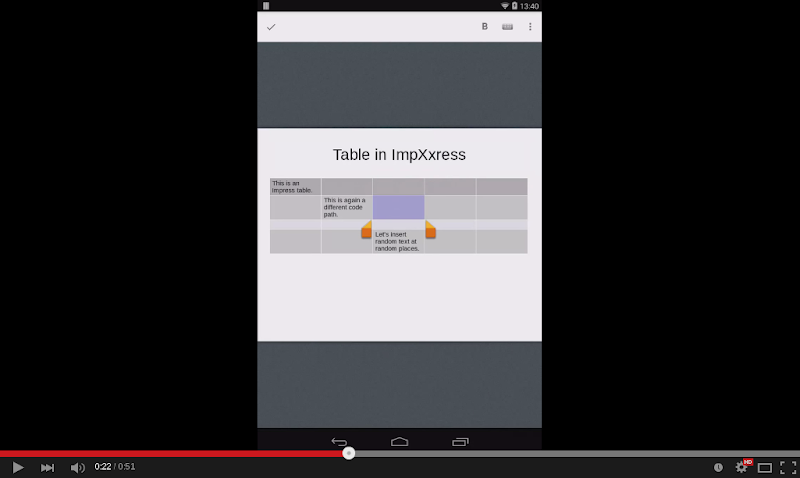
For many of the above features, the core part was already implemented due to Writer shapes, what was missing is to call the same editeng methods from Impress and/or do missing core coordinates → LOK coordinates conversions. The later is twips for both cases in Writer, but Impress works in 100th millimeters internally, so it was necessary to do a number of conversions here and there so that LOK callbacks always emit coordinates in twips.
We also prepared more in-depth technical documentation about the Android
editing work, libreofficekit/README and android/README now has much more
details about how exactly the editing works.
That’s it for now — as usual the commits are in master (a few of them is only in feature/tiled-editing for now), so you can try this right now, or wait till the next Tuesday and get the Android daily build. :-)